728x90
반응형
LangChain으로 만드는 텍스트 요약 예제

소개
이 포스팅에서는 LangChain을 사용하여 텍스트 요약기를 만드는 방법을 알아보겠습니다. 최근 LangChain API의 변경사항을 반영하여 코드를 업데이트했습니다.
준비 사항
시작하기 전에 다음 사항들을 준비해주세요:
- Python 3.7 이상 설치
- OpenAI API 키 (https://openai.com에서 얻을 수 있습니다)
- 필요한 라이브러리 설치:
pip install langchain langchain-openai python-dotenv
코드 구현
다음은 텍스트 요약기의 업데이트된 전체 코드입니다:
import os
from dotenv import load_dotenv
from langchain_openai import OpenAI
from langchain.chains.summarize import load_summarize_chain
from langchain.docstore.document import Document
# .env 파일에서 환경 변수 로드
load_dotenv()
# OpenAI API 키 확인
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY가 설정되지 않았습니다. .env 파일을 확인해주세요.")
# 언어 모델 초기화
llm = OpenAI(temperature=0)
# 요약 체인 로드
chain = load_summarize_chain(llm, chain_type="map_reduce")
def summarize_text(text):
# 텍스트를 Document 객체로 변환
doc = Document(page_content=text)
# 요약 실행
summary = chain.run([doc])
return summary
# 테스트용 텍스트
test_text = """
A transformer is a deep learning architecture developed by Google and based on the multi-head attention mechanism, proposed
in a 2017 paper "Attention Is All You Need". Text is converted to numerical representations called tokens, and each token is
converted into a vector via looking up from a word embedding table. At each layer, each token is then contextualized within
the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism allowing the
signal for key tokens to be amplified and less important tokens to be diminished. The transformer paper, published in 2017,
is based on the softmax-based attention mechanism proposed by Bahdanau et. al. in 2014 for machine translation, and the Fast
Weight Controller, similar to a transformer, proposed in 1992. Transformers have the advantage of having no recurrent units,
and therefore require less training time than earlier recurrent neural architectures such as long short-term memory (LSTM).
Later variations have been widely adopted for training large language models (LLM) on large (language) datasets, such as the
Wikipedia corpus and Common Crawl. This architecture is now used not only in natural language processing and computer
vision, but also in audio, multi-modal processing and robotics. It has also led to the development of pre-trained systems,
such as generative pre-trained transformers (GPTs) and BERT (Bidirectional Encoder Representations from Transformers).
"""
# 요약 실행
summary = summarize_text(test_text)
print("요약:")
print(summary)주요 변경사항 설명
1. invoke 메서드 사용
def summarize_text(text):
doc = Document(page_content=text)
summary = chain.invoke([doc])
return summary['output_text']이전 버전의 run 메서드 대신 invoke 메서드를 사용하도록 변경했습니다. invoke 메서드는 딕셔너리를 반환하며, 요약된 텍스트는 'output_text' 키에 저장됩니다.
실행 결과
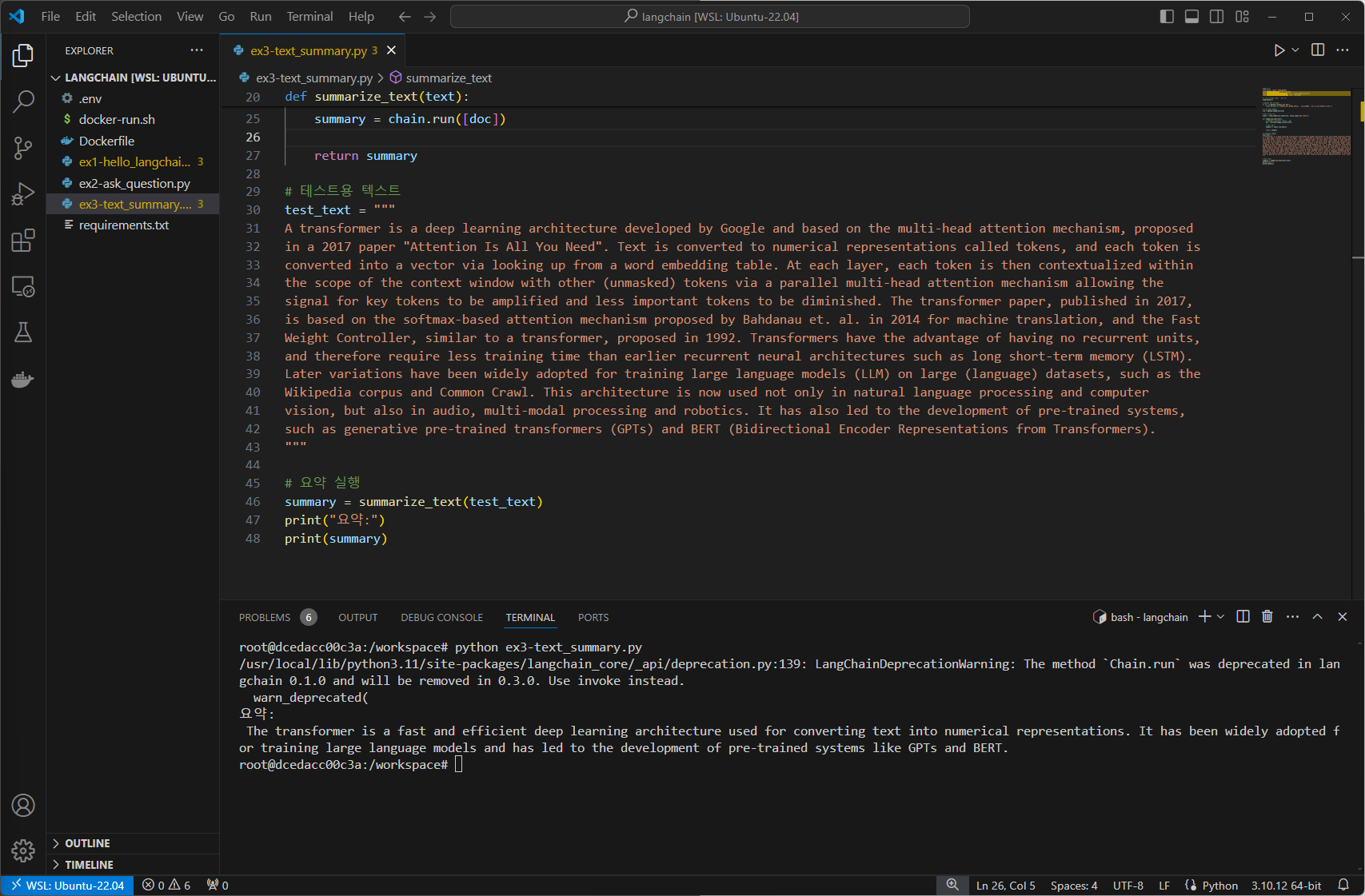
위의 코드를 실행하면, 주어진 텍스트에 대한 요약이 생성됩니다. 실제 출력은 AI 모델의 특성상 매번 조금씩 다를 수 있지만, 대략 다음과 같은 내용이 출력 됩니다.
요약:
The transformer is a fast and efficient deep learning architecture used for converting text into numerical representations. It has been widely adopted for training large language models and has led to the development of pre-trained systems like GPTs and BERT.결론
이 업데이트된 예제에서는 LangChain의 최신 API를 사용하여 텍스트 요약기를 구현했습니다. invoke 메서드를 사용함으로써 더 모던하고 안정적인 코드를 작성할 수 있게 되었습니다. LangChain과 OpenAI의 GPT 모델을 조합한 이 요약 시스템은 긴 문서나 글을 효과적으로 요약하여 핵심 내용을 빠르게 파악하는 데 도움을 줄 수 있습니다. 이 튜토리얼이 여러분의 LangChain 학습 여정에 도움이 되었기를 바랍니다.
반응형
'인공지능 > Lang Chain' 카테고리의 다른 글
| LangChain을 이용한 MP3 음성 파일 STT 구현하기 (0) | 2024.06.29 |
|---|---|
| LangChain과 gTTS를 활용한 동적 TTS 시스템 구축하기 (0) | 2024.06.29 |
| 간단한 Python TTS 애플리케이션 만들기: gTTS 활용하기 (0) | 2024.06.29 |
| LangChain으로 만드는 간단한 질문-답변 시스템 (0) | 2024.06.29 |
| LangChain 소개와 가장 간단한 예제 (0) | 2024.06.29 |



