728x90
반응형
LangChain을 이용한 MP3 음성 파일 STT 구현하기
LangChain과 OpenAI의 Whisper 모델을 사용하여 MP3 음성 파일을 텍스트로 변환하는 STT(Speech-to-Text) 예제를 구현하는 방법을 소개하겠습니다.

1. 예제 프로젝트 개요
이 프로젝트의 목표는 다음과 같습니다.
- LangChain을 사용하여 MP3 파일을 텍스트로 변환
- OpenAI의 Whisper 모델 활용
- 간단하고 효과적인 STT 시스템 구축
2. 필요한 라이브러리 설치
먼저, 필요한 라이브러리를 설치해야 합니다. 터미널에서 다음 명령어를 실행하세요.
pip install langchain langchain-openai langchain-community python-dotenv openai-whisper pydub ffmpeg-python또한, FFmpeg가 시스템에 설치되어 있어야 합니다.
3. 코드 구현
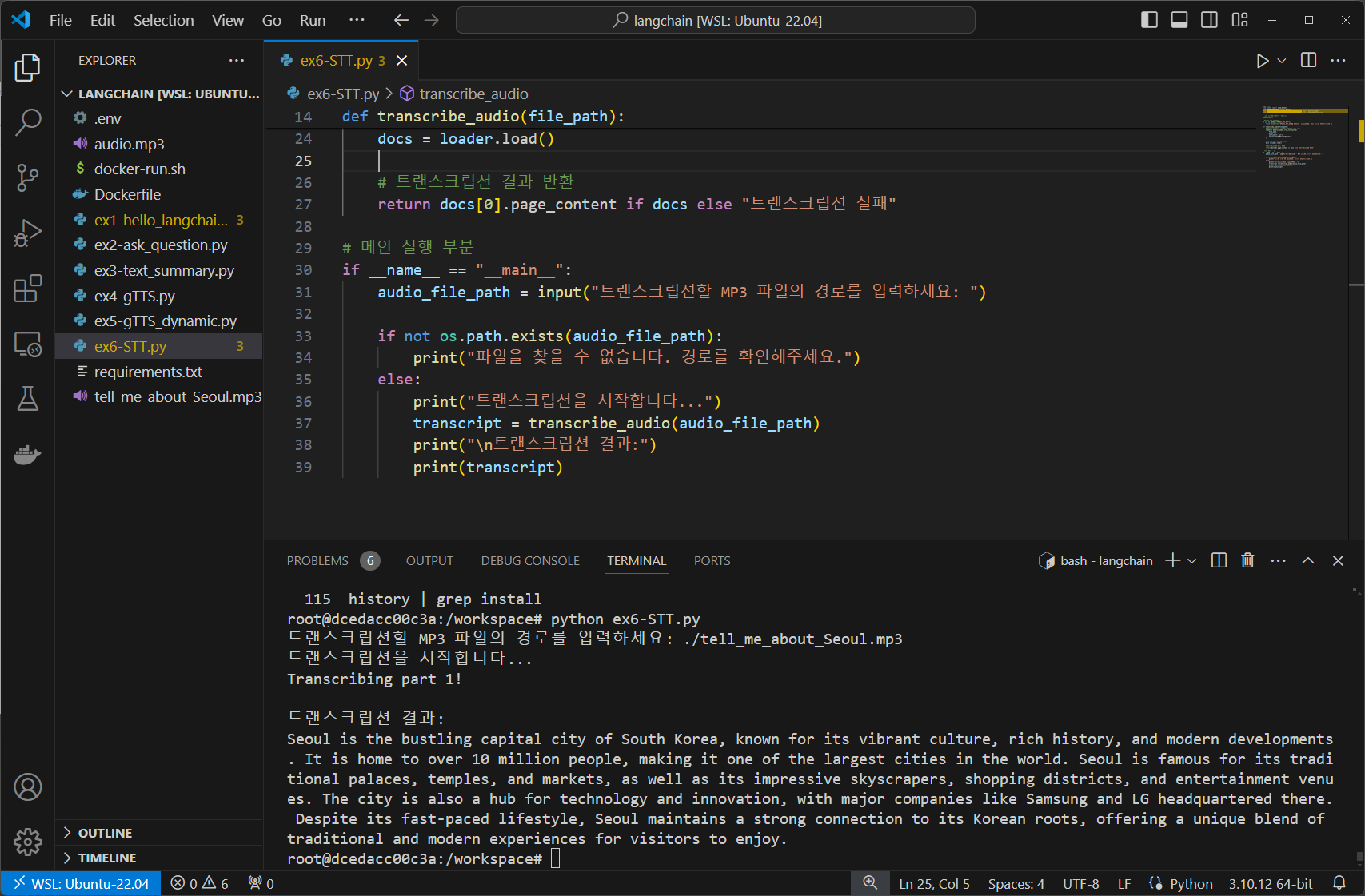
다음은 LangChain을 사용하여 MP3 파일을 텍스트로 변환하는 ex6-STT Python 코드입니다.
import os
from dotenv import load_dotenv
from langchain_openai import OpenAI
from langchain_community.document_loaders.generic import GenericLoader
from langchain_community.document_loaders.parsers import OpenAIWhisperParser
# .env 파일에서 환경 변수 로드
load_dotenv()
# OpenAI API 키 확인
if not os.getenv("OPENAI_API_KEY"):
raise ValueError("OPENAI_API_KEY가 설정되지 않았습니다. .env 파일을 확인해주세요.")
def transcribe_audio(file_path):
# GenericLoader를 사용하여 오디오 파일 로드
loader = GenericLoader.from_filesystem(
file_path,
glob="*",
suffixes=[".mp3"],
parser=OpenAIWhisperParser()
)
# 오디오 파일 트랜스크립션
docs = loader.load()
# 트랜스크립션 결과 반환
return docs[0].page_content if docs else "트랜스크립션 실패"
# 메인 실행 부분
if __name__ == "__main__":
audio_file_path = input("트랜스크립션할 MP3 파일의 경로를 입력하세요: ")
if not os.path.exists(audio_file_path):
print("파일을 찾을 수 없습니다. 경로를 확인해주세요.")
else:
print("트랜스크립션을 시작합니다...")
try:
transcript = transcribe_audio(audio_file_path)
print("\n트랜스크립션 결과:")
print(transcript)
except Exception as e:
print(f"오류 발생: {e}")
print("FFmpeg가 설치되어 있는지 확인해주세요.")4. 코드 설명
- 환경 설정:
load_dotenv()를 사용하여 .env 파일에서 OpenAI API 키를 로드합니다.- API 키가 설정되어 있는지 확인합니다.
- transcribe_audio 함수:
GenericLoader를 사용하여 MP3 파일을 로드합니다.OpenAIWhisperParser를 사용하여 오디오를 텍스트로 변환합니다.- 변환된 텍스트를 반환합니다.
- 메인 실행 부분:
- 사용자로부터 MP3 파일 경로를 입력받습니다.
- 파일 존재 여부를 확인합니다.
- 트랜스크립션을 실행하고 결과를 출력합니다.
- 오류 처리를 통해 예외 상황에 대응합니다.
5. 실행 방법
1..env 파일에 OpenAI API 키를 설정합니다:
OPENAI_API_KEY=your_api_key_here2.스크립트를 실행합니다:
python ex6-STT.py3.프롬프트가 표시되면 MP3 파일의 경로를 입력합니다.
6. 주의사항 및 팁
- OpenAI API 사용에 따른 비용이 발생할 수 있으니 주의하세요.
- 큰 오디오 파일의 경우 처리 시간이 오래 걸릴 수 있습니다.
- Whisper 모델의 다양한 언어 지원을 활용해 보세요.
- 프로덕션 환경에서는 적절한 에러 핸들링과 로깅을 추가하는 것이 좋습니다.
이 프로젝트를 통해 LangChain과 OpenAI Whisper를 사용하여 간단하지만 강력한 STT 시스템을 구현해 보았습니다. 이 기술은 음성 데이터 분석, 자동 자막 생성, 음성 명령 처리 등 다양한 애플리케이션에 활용될 수 있습니다.
LangChain의 유연성과 OpenAI Whisper의 강력한 성능을 결합함으로써, 개발자들은 복잡한 음성 처리 작업을 비교적 쉽게 구현할 수 있게 되었습니다. 이는 AI 기술의 접근성을 높이고, 더 많은 혁신적인 애플리케이션의 개발을 가능하게 합니다. 다른 AI 기술과 결합하여 더욱 강력하고 유용한 애플리케이션을 만들어 볼 수 있을 것입니다.
반응형
'인공지능 > Lang Chain' 카테고리의 다른 글
| LangChain 랭체인의 구조 (0) | 2024.06.30 |
|---|---|
| LangChain과 gTTS를 활용한 동적 TTS 시스템 구축하기 (0) | 2024.06.29 |
| 간단한 Python TTS 애플리케이션 만들기: gTTS 활용하기 (0) | 2024.06.29 |
| LangChain으로 만드는 텍스트 요약 예제 (0) | 2024.06.29 |
| LangChain으로 만드는 간단한 질문-답변 시스템 (0) | 2024.06.29 |



